DeepSeek: A Trillion-Dollar AI Tornado
I had always wondered what would get me to write again. Many who know me know that I used to write regularly a few years ago, but allowed life to get in the way. A shame, because writing and taking notes have always been my way of making sense of the world around me.
Anyhow, I got my answer a few days ago when an obscure hedge fund in China released an AI model that wiped nearly a trillion dollars of value in the public markets. As far as catalysts go, it’s a pretty legitimate one to pick up the pen again..
In this essay, I aim to explain (mostly to myself) why the markets freaked out, and whether it was justified. The essay is my journey from concepts that I know to concepts only esoteric AI researchers would understand. I’m not shy, and never have been, about exposing the boundaries of my expertise. I most certainly got a few things wrong. The Cunningham effect states: “The best way to get the right answer on the Internet is not to ask a question; it's to post the wrong answer.” So if you spot an errorr and correct me, I’ll owe you one.
As I reflect, the DeepSeek announcement ignited three confounding and intermingling wars, each shaping the Trillion Dollar Tornado:
Technical Supremacy: A battle between DeepSeek’s technical advancements relative to the AI products developed by US companies (OpenAI, Anthropic, Meta, etc).
Distribution Modalities: A battle between open-source models like DeepSeek (they made their work available for free, for anyone to build on top of) and closed models like OpenAI and Anthropic
Geopolitical Undercurrents: A wake-up call to the US vis-a-vis China, especially as we in the West love to tell ourselves that we’re ahead of the Chinese in AI technologies (all the while ceding ground in most other critical technologies).
My thoughts on each are:
Technical Supremacy: This is what I spent most of my time understanding and writing about
Distribution Modalities: This remains a topic I seesaw on, which tells me I need to refine my thinking further—perhaps a topic for another essay
Geopolitical Undercurrents: My father was a career diplomat, so I’ve been exposed to these discussions all my life, but AI policy isn’t my primary focus. That said, a few key points stand out:
a. We should restrict sending our best computing hardware to China by way of enforcing export controls, but determined actors find a way to get what they want. We should act as if export controls will be toothless, and aim to compete on pure merit with foreign labs.
b. Necessity is the mother of invention - which is why DeepSeek emerged. The Chinese pushed the limits of AI math with DeepSeek because, absent advanced compute hardware, they had no other option.
c. If all else fails, the Chinese can distill US models - which is to say that they can (very roughly) recreate the inner workings of our best models with some clever computer engineering on their end. Which brings me back to point (a) above - we in the West are left with no other option too but to continue innovating on pure merit!
In summary, I want to investigate mostly technical-ish questions in this essay, some of which are:
What about this new DeepSeek model is technically better than State Of The Art (SOTA) AI models from US companies like OpenAI, Meta, Anthropic?
Was DeepSeek really trained for a fraction of the cost of SOTA training?
Was the media hype, and the resulting Trillion Dollar Tornado, justified?
By the time I finished writing, many experts had already dissected these questions. The answers are:
That’s what this essay ends up being about. Read on.
It was, and it wasn’t. This is the definitive article you want to read if the training costs of DeepSeek are what keep you up at night. TL;DR - some of the cost savings are totally explainable by technological advances that every AI player in the world will benefit from today. Other savings are more sleight of hand.
No. Not at all. This is just the exciting beginning for all players – especially those in the picks and shovels business.
OK, let’s go.
The Basics:
(aka AI for Dummies VCs those who don’t do this for a day job)
I will try to bold AI jargon throughout the article.
This entire brouhaha was about a Large Language Model (LLM), which is a program that is extremely good at predicting the next word that follows a string of words. Massively simplifying here, but if your input to the LLM was “the dog eats a..”, there’s a very high likelihood that the LLM finishes it with the word “..bone” because that’s the word it has seen occur most frequently in the context of canines eating [1].
A Large Language Model (LLM) is a type of neural network, a class of computer programs that recognizes patterns like a human brain would and is designed to learn in the same way a human brain does. A neural network is made up of nodes that are connected, like neurons in a brain. The network learns by tweaking the strength of the connections between these nodes.
Figure 1 Neural Network Node
A neural network needs to be trained, much like teaching a toddler, by showing real-life examples of text, images, videos. As it sees more known input and trains on them, the model learns to reason better when presented with unknown inputs. Training and Reasoning are two recurring terms in this essay, and in any AI conversation.
All of this is conceptual stuff but it sets the table. Let’s make things real by going all the way back to…6th grade.
Remember y = mx + b ? AKA the straight line equation.
The above equation is the simplest entry point into the world of AI models, neural networks, and other AI jargon that I could think of [2]. It also shares some of the same terminology:
‘m’, i.e. the slope of the line is the weight of this function
‘b’, i.e. the Y-intercept is also called the bias of this function
‘x’ is the input to the neuron
‘y’ is the output of the neuron
The total number of weights and biases in a model refers to its parameters. So in the above straight line equation example, we have 2 parameters = 1 weight (i.e. ‘m’) and 1 bias (i.e. ‘b’). Think of each parameter as a single knob you can tweak. A small model might have a few knobs; a huge model might have billions.
A large language model (LLM) has millions of tiny equations like the one above working together. y = mx + b predicts a numerical value. LLM equations go further – they don’t just predict one number, they predict the probability of the next word based on everything written so far.
Just like in our equation, where ‘m’ (the slope) determines how much X influences Y, LLMs parameters determine how much each past word influences the next. Instead of a straight line, though, these weights form a complex network - like thousands of interwoven patterns instead of a single slope.
When I asked the LLM to finish the expression “The dog eats a…”, these are the options it considered, the probabilities it assigned to the next word being the correct one, and the reason it thought why:

Table 1 LLM Word Prediction and Probability Distribution
Millions of little equations worked on the backend to inform the model that the word “bone” had the highest probability (40%) of being right, so the LLM went with it.
An LLM at its core consists of two basic files:
One file contains all the parameters of the large language model. This could be millions, billions, or even trillions of parameters
The other file is a list of instructions on how to get the model to work. The LLM refers to this file to determine how it should generate a response—adhering to tone, length, safety filters, and contextual rules
The more parameters a model has, the more sophisticated its worldview is. I like to think of it this way - a kindergartner's brain has more parameters than an infant’s brain, because its neural pathways are more developed. A high-schooler’s brain has more parameters than a kindergartner’s, and someone with a PhD has even more parameters than a high-schooler would.
What are the implications of having more parameters vs fewer? For one, more parameters generally require more training - a PhD is earned after 20 years of formal education, after all! Secondly, generally with more parameters, you can reason better when confronted with unknown situations.
More parameters, generally, means more intelligence. But it also costs a lot more to train/educate them. More parameters also require more computer memory to store. Take Meta’s open-source LLaMa2, for example – it has 70 billion parameters. Each parameter is stored using 16 bits (2 bytes), which means that the entire model occupies 70 billion x 2 bytes = 140 gigabytes (GB) of storage.
How much usable storage (RAM) do you have on your phone, or even laptop? Chances are, much less than 140 GB. Which means you cannot run the 70 billion parameter version of LLaMa2 on your phone or laptop. Perhaps a 3 billion parameter version is better suited for personal computing devices today. But since it has fewer parameters, it won’t be as intelligent.
Training an LLM:
Let’s go back to 6th grade math for a second – our trusted y = mx + b. Recall that if I gave you at least two points on an XY plane, you can draw a line through them. In doing so, you can train the linear equation model and assign numerical values to the weight “m” and the bias “b”.
Turns out we’ve all been training models since middle school.
Simple models, like the above example, can be trained in one step:
Unstructured data —-> Training / Curve fitting —> Trained model ready
Back to LLaMA2. It was trained on 10 terabytes of text [3]. The process took 6000 GPUs, 12 days, and roughly $2M in training cost. LLaMa2 was trained in early 2023, using data that was cutoff in September 2022.
Compared to simpler models, LLM training takes 2 or 3 steps. Each step makes the model smarter, but also costs time and money as a tradeoff. The steps are:
Step 1: Pre-training
Imagine you want to learn about quantum computing but know nothing about it. You grab the textbook on the subject and read it cover to cover. It takes you many days, you consume many a Diet Coke in the process, but you’re finally done. In an LLM context, you have pre-trained yourself on quantum computing. Are you any good at quantum computing just yet? Nah. But you have a faint idea of what’s going on and can potentially muster an intelligent sentence or two if asked nicely.
Pre-training an LLM is no different. Grab reams upon reams of text data, put it in your black-box model, and out comes a “base LLM.” The process follows a simple flow:
Unsupervised data —> Pre-training —> Base LLM
Pre-training costs a lot of money (Anthropic’s Dario Amodei has publicly stated spending “tens of millions” to train Claude 3.5 Sonnet) for two main reasons. Every AI company working on a model needs:
Access to compute
Access to unsupervised data
I don’t know the % split of costs here but I’d wager it is >99% the former, and <1% the latter. AI companies need raw compute power, which is why Nvidia has been making money hand over fist. They also must pay the likes of NYTimes, Reddit, Wall Street Journal, publishers of textbooks, scientific journals, and anyone with quality content to train their models on.
Over time, an LLM can be trained on the output of other models. This process is called distillation. It is kind of an open secret in Silicon Valley that many new models train on the output of models from other companies.
Step 1 of training an LLM takes a lot of time and lots of dollars, which is why the likes of Sam Altman wanted to raise $7 trillion at one point.
Step 2: Supervised Fine Tuning (SFT)
If I continue my “learn quantum computing by reading a textbook” analogy, SFT would mean you’ve hired a tutor who is an expert in Quantum Computing who is willing to show you some problems and how she has solved them. You’ll passively observe how she approaches the problems, taking note of how she avoids certain pitfalls, or stresses certain behaviors. Just seeing the work of an expert makes you better off.
In the context of an LLM, SFT can take the form of humans writing a question for the model, as well as writing a good answer for it. The model then learns what’s expected from it when similar questions are asked - the tone of the reply, the length, the veracity. SFT ensures that the model isn’t too woke, too prone to hallucinations, etc.
The output of the SFT stage is called an Assistant Model. An Assistant Model is cheaper to train than a base model and can be refreshed much more frequently.
Step 3: Reinforcement Learning
While Supervised Fine-Tuning teaches the model through direct examples, Reinforcement Learning allows it to improve by trial and error.
In the “learning Quantum Computing by reading a textbook” analogy, Reinforcement Learning would require solving the problems on the back of a textbook. You know the problem, you know the final answer, but you have to figure out a way to get to the final answer. There will be starts and stops, you’ll get into cul-de-sacs and may have to back out from them, but knowing the final answer and getting to it yourself is the underpinning of RL. If the tutor you hired in Step 2 is still around and willing to give you hints to help you get to the final answer, this process is called Reinforcement Learning with Human Feedback (RLHF).
To recap all the jargon, training an LLM takes three steps:
Pre-training - costs a lot, akin to reading a book cover to cover
Supervised Fine-tuning - cheaper than Pre-training, akin to reviewing solved problems in the textbook
Reinforcement Learning - learning by trial and error, akin to solving the problems at the back of the book
Reasoning/Inference in an LLM:
Once an LLM is trained and its parameters are fixed (through the steps above), the next big question is: How does it actually “think” and produce answers? This phase is called Inference. In simple terms:
Prompt In, Answer Out
When you type a question or a prompt into the LLM (e.g., “Explain quantum computing in simple terms”), the model uses what it has “memorized” or “understood” from training to predict the most likely next word (or token), then the next, and so on.Pattern-Based Reasoning
The LLM’s training allows it to pick up on massive patterns—things like grammar, topic transitions, and even logical structure. During inference, the model’s internal mechanism uses these patterns to figure out the best response. This process is called reasoning because it looks surprisingly human-like. Under the hood, it’s really a rapid sequence of mathematical predictions guided by patterns learned during training.Chain-of-Thought and Context
Modern LLMs can keep track of the conversation —this is often referred to as a context window. This means the model can reference previous parts of the conversation or question, giving it the appearance of multi-step thinking (a chain of thought or CoT). The longer and more complex the conversation, the more the model needs to rely on that context to generate coherent answers.Why the LLM Feels “Intelligent”
Because the LLM was exposed to millions (or billions) of documents, it has effectively learned how various topics connect, how arguments flow, and even how to perform basic reasoning tasks. This makes it seem like it “understands” things in a deep way. In reality, it’s drawing from an enormous web of correlations gleaned from the text it was trained on.
In short, inference is the process of turning a trained model’s learned patterns into actual responses. Behind the scenes, it’s just the model rapidly predicting the next word based on everything it has seen before.
Imagine you were running an AI lab and could wish for a miracle. What might you wish for? It wouldn’t be wrong to say that you’d want to train your model extremely cheaply (using far less compute than your competitors) while having it be more intelligent than even humans in its reasoning abilities. That would be the ultimate miracle, right?
Check this out:

Figure 2 AI Performance on Set of Ph.D.-level Science Questions
Take a minute to digest this graph (beautiful work by Epoch AI).
There’s only one model that surpasses expert human level science reasoning. Which brings us to….
DeepSeek:
We arrive at DeepSeek. The Trillion Dollar Tornado. Finally!
I have to make a quick disambiguation. The word DeepSeek has been used carelessly on Twitter and by the media. When people say DeepSeek, they might be talking about one of three things:
The app called DeepSeek: This was the most downloaded AI app for a small period of time. This app sends your data back to China. The app tells you that Tiananmen was a figment of your imagination, and that Taiwan is a part of China. The DeepSeek app is bad news all around and it’s not something I want to spend time talking about.
The open-source base model released in December 2024 called DeepSeek-V3: This is the release that should have tanked many an AI stock, but didn’t. Perhaps because it was too dense for the media to report on. The DeepSeek-V3, or the -V3, is a general-purpose base LLM optimized for efficiency and scalability. I am a fan of this corpus and will explain this in some more detail.
The reasoning model released in January 2025 called DeepSeek-R1. It is an impressive piece of engineering, was trained with little to no Supervised Fine Tuning, and shows in real time how it is responding to requests using Chain of Thought. It’s what crashed the markets – in part because seeing CoT in action is cool, and in part because the paper was easier to understand.
The media, in its carelessness and wanting to scoop a story, took two data points, one from each DeepSeek model (-V3 and -R1) and wove a narrative so scary that it spooked the markets more than the scariest horror stories could:
From the -V3 paper, the media picked up “$5.5M in training costs”. The US labs, after all, were spending hundreds of millions to train their AI models, so how come the Chinese got it done for a fraction?
From the -R1 paper, the media latched onto “...achieves performance comparable to OpenAI-o1-1217”. So not only did they train their base model for far, far less, their reasoning model is as intelligent as Open AI’s latest? What the….
Add the spiciness of the model coming out of China. The headline practically writes itself: “New Chinese model beats American AI at a tenth of the cost.”
If folks in the media or talking heads on Twitter actually used an AI product (e.g. Perplexity), they’d likely have worded the headline as: “Chinese mathematicians find clever ways to train a model at a low-but-unverifiable cost, and the model is as good at reasoning as a US model that was trained about a year ago.” But it’s not a sexy headline and would’ve gotten zero clicks.
Also, given how rapidly AI is advancing these days, a Large Language Model that was trained a year ago is already lagging behind by 4 generations. Let me repeat - an AI model lags behind four generations of upgrades and advancements in just a year! This makes an LLM “one of the fastest depreciating assets in technology.” Which also means that this model should have cost roughly 4x less to train today than it did a year ago. Should’ve been hint # 1 for anyone commenting on DeepSeek [4].
Still – there is so much to love about the two models. That first paper (-V3) is the real cake, the second (-R1) a delicious cherry on top.
DeepSeek-V3:
(TL;DR - if you want to make a faster car, you can choose to out-innovate competitors on the size of the engine. You can go from a V4 engine block to V6 to V8, and so on. This is what the US AI labs have been doing thus far. DeepSeek didn’t have access to advanced engine-makers, so it was forced to do things like making the car more aerodynamic, fine tuning fuel-injection, making the seats and interiors lighter in mass, to achieve comparable fast speeds with smaller engines)
The paper, released in December 2024, states that it is a “Mixture-of-Experts (MoE) language model with 671 Billion total parameters.” Hey, I recognize some of those words!
What is a Mixture-of-Experts model? It is an architectural approach in machine learning that chops up a big (aka ‘dense’) AI model into smaller sub-networks or "experts," each specializing in a subset of input data. The MoE model is your high-school friend who always 'had a guy'—a specialist for every problem. The model also has a rolodex of sorts (a gating function in AI jargon) that decides which expert to call on for a given input.
The experts aren’t pre-determined, they naturally emerge during training of the MoE model. Some real-life examples of experts in a MoE model include:
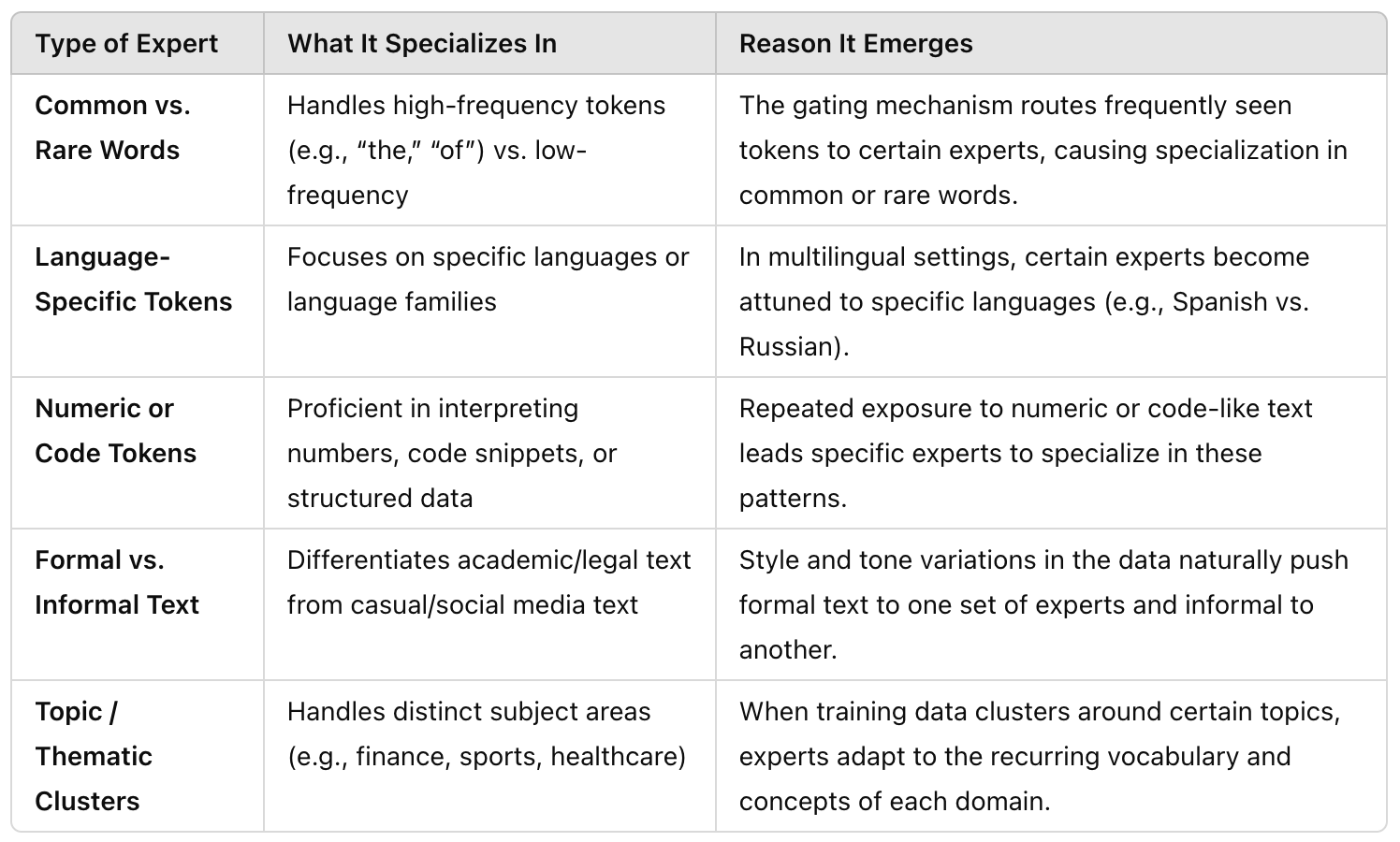
Table 2 Expert Specialization in a Mixture-of-Experts (MoE) Model
Instead of diving deeper inside an MoE architecture (because it’ll require spending another dozen hours wading through deep math), I took a shortcut and just asked myself:
Is the MoE architecture new?
Why wasn’t it widely used for LLMs before?
The answers are:
Not new at all – the concept was first published in 1991.
It (kind of) was. xAI’s Grok, Mixtral, many companies have used the MoE architecture. Even OpenAI’s GPT-4 is likely an MoE model. But because OpenAI is anything but open, we’ll not be able to confirm the inner workings until a year or two from now.
DeepSeek’s innovation isn’t entirely greenfield, AKA a 0 → 1, but many great inventions involve perfecting the work of others.
As I read more, I learnt some more cool things about an MoE model:
Mixture of Experts (MoE) model can be more compute-efficient per training step (because you only train some experts for each input). Stands to reason why DeepSeek could train its model at a fraction of the cost of other players.
It has higher memory requirements than a ‘dense’ model like LLaMa because a MoE model requires 2-4x as many parameters, which must all be loaded into the memory at the same time. Likely why it hasn’t been a frequently implemented AI model architecture (up until now).
Lastly, and most importantly, an MoE model has been extremely hard to train thus far. Up until DeepSeek came along, a traditional MoE model trained like an eager gym bro that was all pecs and biceps, but was never seen training legs or back. The biggest challenge with training a network of experts has been that some experts get over-trained and end up doing the heavy lifting for the entire model, while other experts get no love during the training process. This translated into sub-optimal outputs during inference.
DeepSeek-v3 addressed the problems posed by # 2 and 3 above – uneven expert training and excessive memory usage:
Old MoE models overtrained some experts, neglected others. This would lead to inferior outcomes when the model was asked to reason. DeepSeek-v3 dynamically adjusts expert usage, making sure the training is a “full body workout.” DeepSeek-V3 is like a smart gym that auto-adjusts the resistance of its machines – if the squat rack is empty, it will subtly make bench presses heavier and heavier, until gym bros migrate to the squat rack and start training legs instead.
A pretty significant advancement by DeepSeek allows MoE models to save 93.3% of GPU memory. Imagine you’re trying to hold a conversation while remembering every single word you’ve ever said thus far. Your brain would get clogged. That’s what happens to AI models today. DeepSeek invented “CliffNotes for AI memory” - instead of memorizing every single detail, the model only stores key patterns and rebuilds details when needed using those patterns. This allows the model to have longer conversations, without necessitating heavy memory requirements.
Uses an 8-bit format instead of 16-bits to be far less computationally intense. Most AI models defaulted to 16-bit or 32-bit instructions - requiring more computation resources.
Instead of using all specialized experts, DeepSeek used 32 shared experts and 224 specialized ones. This allows the MoE to function and train better. If you’re in the mood to get slightly more technical, this is an excellent resource.
Ultimately, what the -V3 model did was innovate with its back against the wall. It's too bad that their app started censoring results and sending data back to China, sullying some stellar statistics.
Lastly, while there was so much technical goodness in their paper, this was the section from the paper that the media took notice of:

Table 3 Training Costs of DeepSeek-V3, Assuming the Rental Price of H800 is $2 per GPU Hour
If I’ve left you hungry to learn more, I suggest this link.
DeepSeek-R1:
(TL; DR - if you want to win a race through unfamiliar terrain, the US AI labs will give you a V8 car with preloaded maps, maybe even a human navigator to go along. DeepSeek-R1, instead, will give you a self-correcting navigating system that detects wrong turns mid-journey and constantly adjusts steering to stay on course. This scrappy driver outsmarts decked-out competitors, but oftentimes will end up in the ditch.)
Producing -R1, given -V3, was probably not too hard. DeepSeek-R1 is the reasoning model that uses DeepSeek-V3 as base model and uses little to no SFT, and instead primarily uses Reinforcement Learning to create a reasoning model like OpenAI’s O1.
What is Reinforcement Learning? It is a learning strategy where an AI system learns through trial-and-error to maximise rewards. What is the reward? Well - the reward is getting the right answer to a given question. After each action the AI system takes, it gets feedback and adjusts its behavior accordingly. Over time, it discovers the best strategy to get the right answer in a changing environment.
The key innovations of DeepSeek-R1 are:
It (nearly) got rid of the SFT training step. This can unlock substantial savings for AI model development over time. It did so by a technique called Group Relative Policy Optimization (GRPO). Picture a basketball team practicing free throws. Instead of a human coach manually correcting every player (traditional AI models), the team shoots 5 versions of the same shots, compares which shots were scored and missed, and learns from the group’s collective success. This works great because you don’t need a human coach, no rulebook, it self-corrects and reduces errors (three-pointers that don’t work are simply tossed away)
The model demonstrated its reasoning process. This has earlier been referred to as Chain of Thought. The model showing its thinking is cool to see, but OpenAI released a CoT model within days of the DeepSeek-R1, which means this was simply something that was available to toggle ON all along.
The -R1 model was benchmarked against OpenAI’s o1 mini and was shown to be “more intelligent.” Panic ensued.
Let’s spend a second talking about benchmarking. What are benchmarks? They are a standardized test (like the SAT, LSAT, MCAT) that every AI model must take to see how its answers stack against human-generated / correct answers. These benchmark tests range from math skills, to programming, to language, etc.
The specific benchmarks that -R1 tested for are:
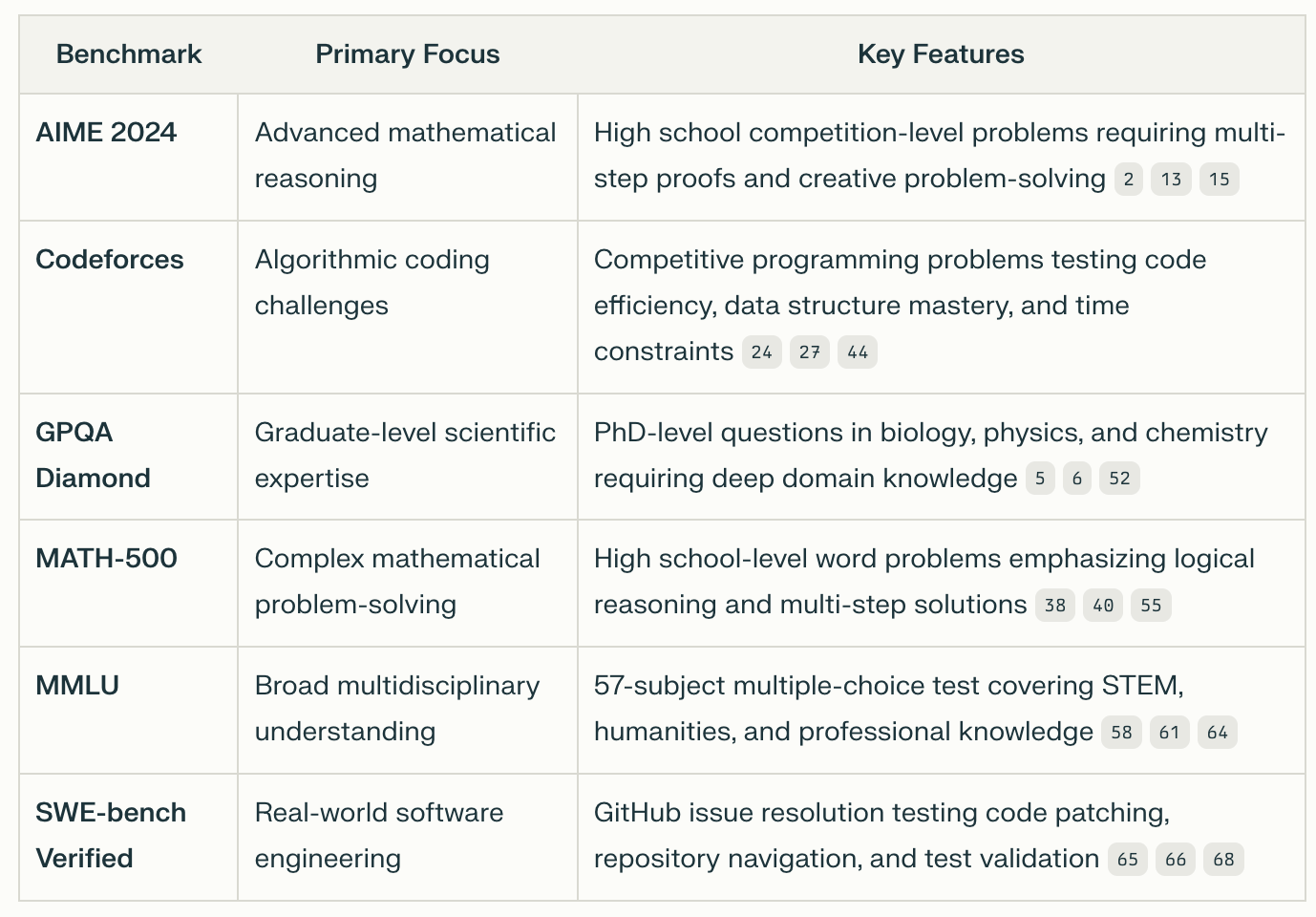
Table 4 LLM Benchmarking
The graph below is what the media saw, and the Trillion Dollar Tornado was born:
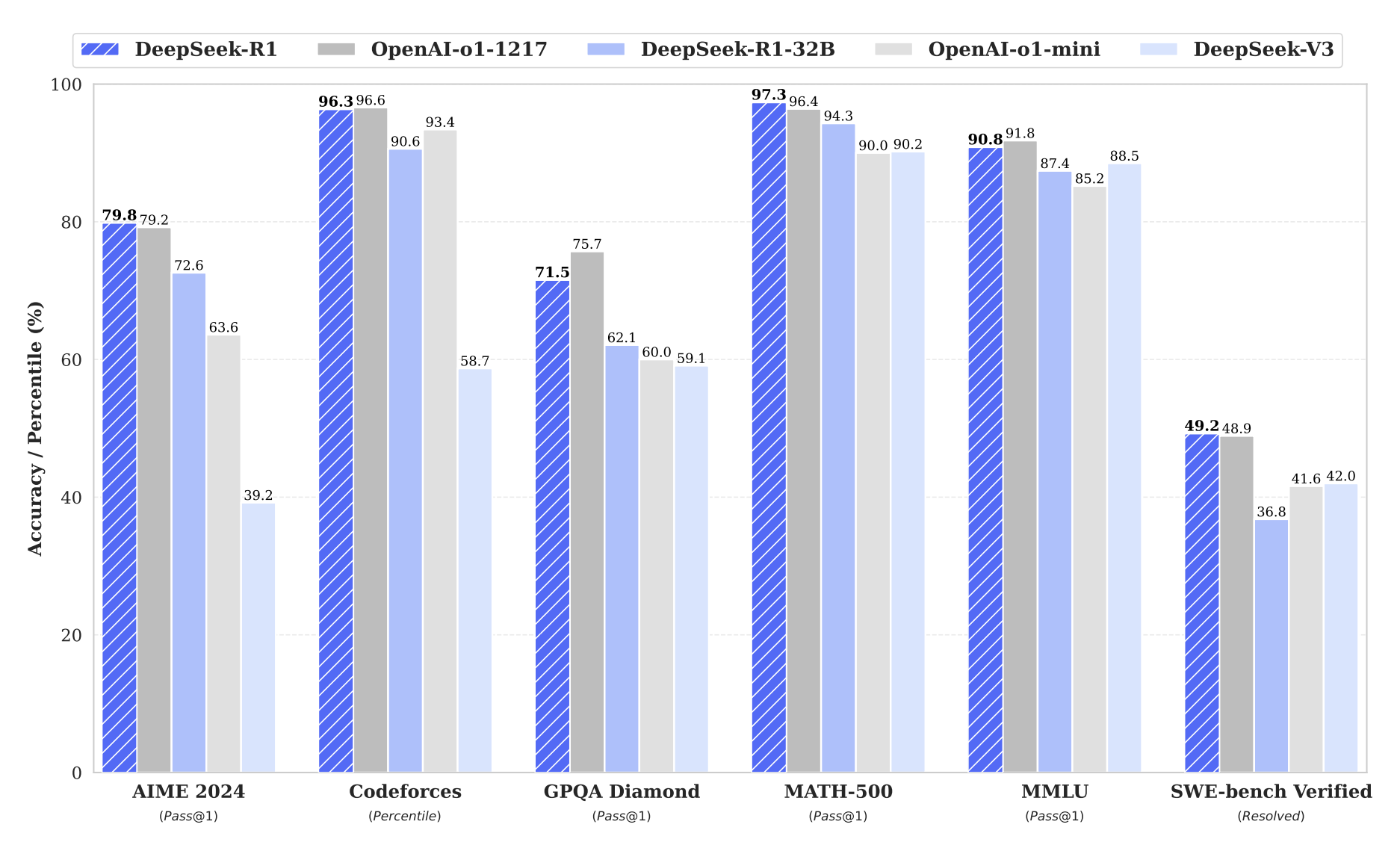
Figure 3 Benchmark Performance of DeepSeek-R1
The bar chart above shows -R1 outperforming OpenAI-o1, and o1-mini on most benchmarks (higher Y-axis value is better). Recall that the -R1 is open-source, so it can do for free what OpenAI has spent billions doing and charges you $200/month for.
I’ll share two more graphs that show how far ahead of the pack -R1 appears to be:

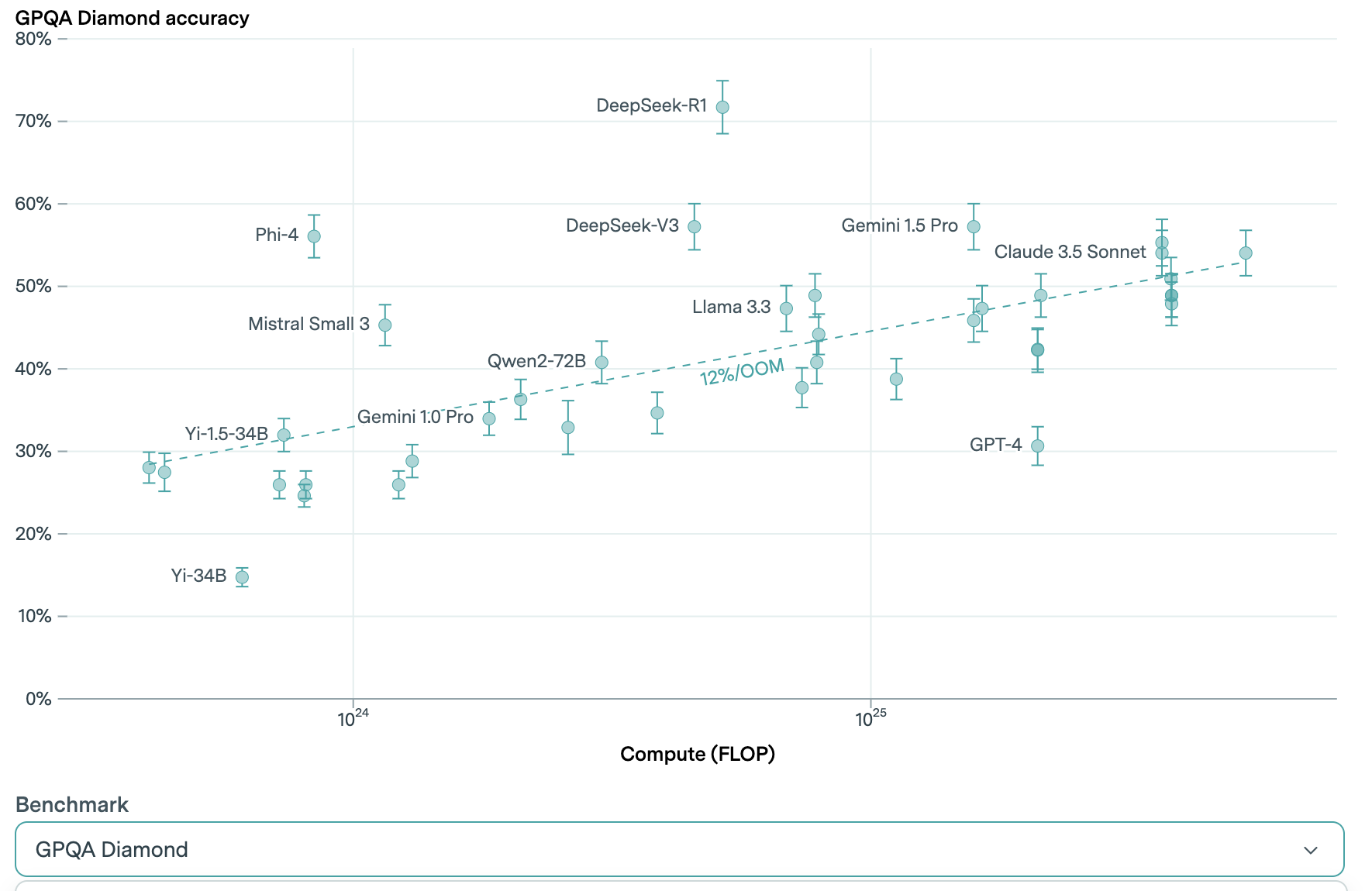
Figure 5 GPQA Diamond Performance of DeepSeek-R1
Look, I should be more impressed by the -R1, but I am reserving the platitudes for two reasons:
Distillation: While a Reinforcement Learning approach is admirable, we can’t be sure what training data went into the model. If the inputs to the -R1 model were the outputs of OpenAI’s o1 model, then of course -R1 will perform as well as OpenAI’s o1 reasoning model. This technique is called Distillation. Distillation is not a bad thing. An open Silicon Valley secret, like I said earlier. My friend Austin (CEO of Aionics AI) wrote a nice article on distillation and concludes with “Once you start looking for it, you can start to see fractals of recursive distillation everywhere. After all, what is a physical model of the world if not a distillation of reality...?!” [5]
If you’re the distiller, you are smart and are using the hard work of others to train your model. If you’re the distillee, you have many reasons to be annoyed.
We just don’t know what happened here.
Data Contamination: Whether by accident or on purpose, the model may have been trained on the exact test it was supposed to take. There is no way to know. If the model knew test problems and its answers ahead of time, then of course it will do great on these benchmarking results.
Is that what may have happened here? I don’t know. Neither do you.
The quality, and the source, of the input data is why I’m gushing less over the -R1 than the -V3.
Also get this – the -R1 model hallucinates at a rate 4x greater than the -V3. This is what I meant in my TL;DR above when I wrote that the “smart-driver” often drives into a ditch.
Here’s some optimism – these types of no-SFT, Reinforcement Learning-only techniques applied to LLM training are very nascent. The amount being spent on the RL stage is small for all players. Spending even modest sums of money in the millions of dollars, as opposed to nil or de-minimis, will unlock huge gains!
In Summary
Writing this essay led me down many rabbit holes, most of which didn’t make their way into this essay. A few things are becoming clear to me:
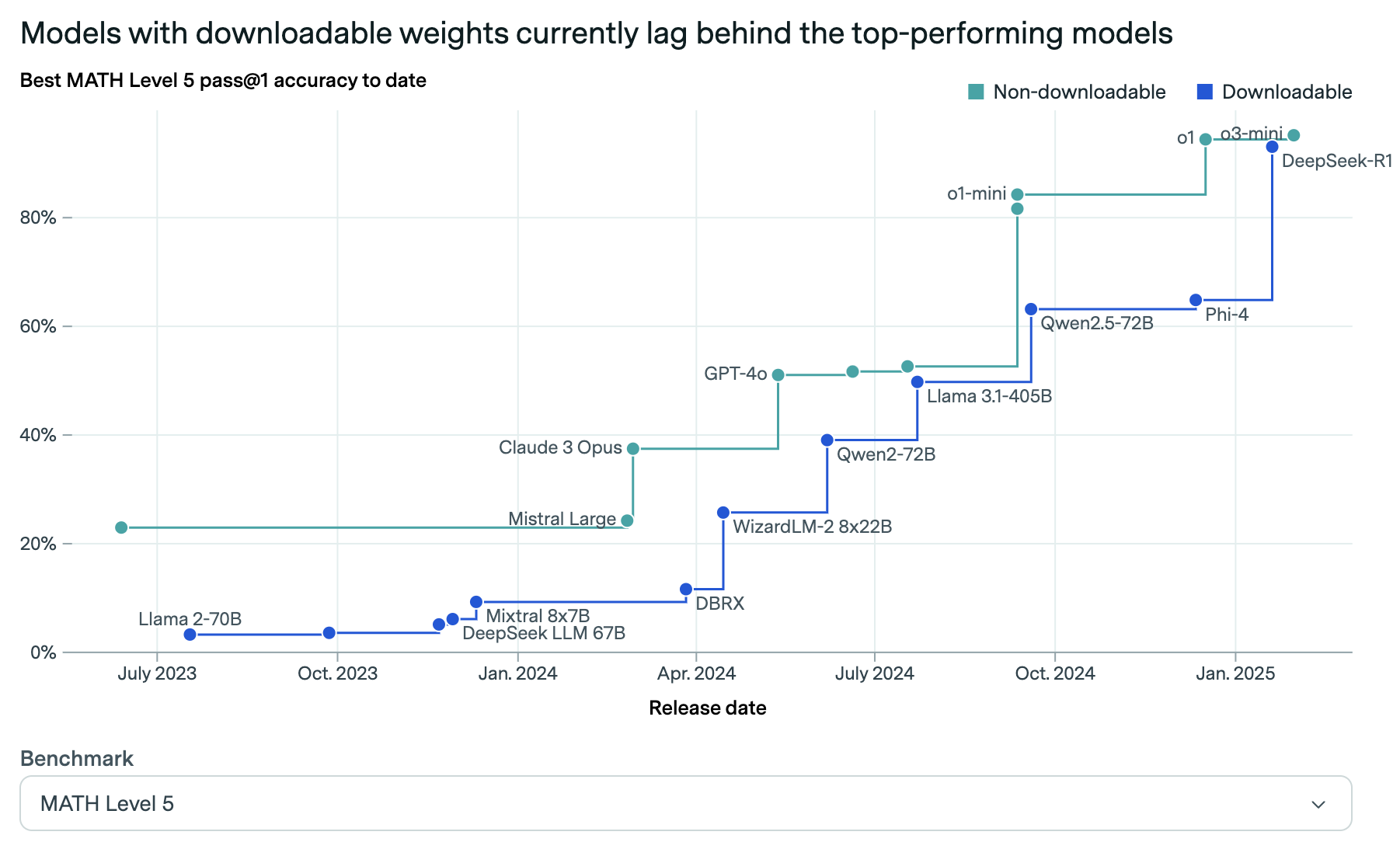
Figure 5 Models Performance on Math Level 5
The DeepSeek team deserves recognition for their achievements. Some argue “this innovation was obvious in hindsight.” They engineered their way out of the constraints they had, open-sourced it, and we all won because of it. An open-source model caught up and closed the gap with closed-source models (see Figure 5 above).
At the “picks and shovels” hardware layer of AI, I continue being bullish on Nvidia, AMD, and Micron. Nvidia and AMD for the compute hardware advancements, Micron for their High Bandwidth Memory product. As my friend Haomiao (General Partner at Matter Venture Partners) said in his excellent essay “there should be no upper limit to intelligence.” We’ll continue needing picks and shovels to spread intelligence everywhere (all over the world, in all sorts of end-point devices) and in every domain (language, medical, scientific).
There probably won’t be a winner-take-all in AI, as many feared. Many AI labs are attacking the problem, all in very novel ways. As long as we have access to compute, to capital, to mathematical trickery, and to human ingenuity, new innovations will continue emerging. There will be many winners.
The media’s reporting on AI is not to be trusted. Many don’t get it. I didn’t either, till I sunk a dozen hours peeking under the hood.
AI model benchmarks are to be taken with a grain of salt. Only feedback and reviews from humans who have used these tools can truly tell if a model is good or not. In researching this article, I’d flip between DeekSeek’s -R1 and OpenAI’s suite of models. I really do prefer OpenAI’s -o1 model - it hit the mark more times than it missed.
The voices in AI that should be trusted are either too quiet, or generate too much hype. I recommend everyone follow Andrej Karpathy - he is a remarkable person who shares his insights because of his love of the AI game. I enjoy Gavin Baker’s takes on X, as well as Epoch AI’s newsletter. Almost everybody else is pushing an agenda or talking their book.
I’m extremely excited. And a bit tired from all this typing.
I’ll go get a drink now.
1. I tried it for giggles: https://www.perplexity.ai/search/finish-this-sentence-the-dog-e-CKdtUl.IT3KhVWupVj6Kyw#0
2. It is not a pure neural network equation, I know, but it is close.
3. I got this figure from Karpathy's intro to LLM video - a good use of your 60 minutes in my view.
4. Gavin Baker was the loudest, and clearest voice about this.
5. He’s a Doctor of Philosophy for sure.